



Does your team have a lot of stale PRs? Does your PR review cycle take a lot of time? This is a common problem for every software developer. I’ve been in a position where my pull request would take a couple of days to get attention, and then addressing the comments from everyone took another couple of days. Meanwhile, the QE/QA would find bugs, and it takes over a week to see the merge button green. Meanwhile, there would be some incidents in the pipeline, some tests failing, or someone else in the team merging before you, and you need to fix those conflicts – I’m sure we have all been there.
In my recent team at WeTransfer, I had the opportunity to solve this problem by introducing a few developer lifestyle changes (duh, do I sound like a dietician?). It is a mix of cultural and technical improvements, and I’m confident you will not go back once you start seeing the benefits.
The secret sauce
I’m going to go ahead and spill the beans (or the sauce) here. The main idea is to create smaller Pull Requests – I know this will sound unexciting and bland for this problem, but this has a domino effect, and the benefits accumulate (like compound interest) in the long run. Some of the benefits include –
- Merging your PRs on the same day
- Knowledge distribution among the team
- Possibly less conflicts
- Possibly less bugs
Creating smaller PRs
I know that smaller PRs may not work for all the teams and in all situations, but the idea is to try thinking about it for every task or pull request. This is the big cultural shift that we enforced within our team – before creating or taking up a ticket we need to ask ourselves – how can I break this work into smaller chunks? Let’s break this down with an example.
Let’s assume a task for ourselves to understand – We need to refactor a function to add additional parameters
Please note that I’m going to stretch (or exaggerate) the process as long as possible, and of course, you need not follow this by the book. You can tailor it according to your situation and problem. Let us also assume the size of the team here. Let’s say a team of 10 devs working on the same codebase (single or multi-module).
PR 1: Deprecating the old method
The first PR is to deprecate the method that we want to change and additional parameters. This PR has nothing to be tested and reviewed. This step ensures that other devs working on other things might not accidentally invoke this or cause a conflict. When the IDE shows a warning, they would definitely reach out to the author on the whereabouts or alternatives.
PR 2: Creating the new method with the additional parameters
The first step and the second one can be combined in a single PR if your are confident on the changes. Now, instead of modifying the existing method, we are creating a new one with all the necessary tests. This will allow the team or the reviewer to review just the needed functions and nothing more. Not more than a couple of files are touched, and the focus is drawn completely to a few functions. Now, no one can have more opinions on this (subjective, yes), and even if they do, addressing it would be a lot faster. Meanwhile, you have blocked other developers from creating conflict, and with this PR, there are only additions. Also, we must point out the deprecated message to use the new methods. Again, this PR has nothing to be tested (except unit tests) as we have not invoked it yet.
PR 3: Replace the call site to invoke the new functions
The next PR is to change all the call sites of the old method pointing to the new one. Since we deprecated the legacy method, the IDE would warn you about this and finding the usage is easier. This can raise questions if it touches the other module owners, but if the contract of the method is respected, we shouldn’t have any blockers. This PR should be moving faster, and this is the part where the product needs to be QA/QE’d – if you are working on feature branches. In our team, we follow a trunk-based model, which gives us additional acceleration to move faster. If you are trunk-based, this PR does not need to wait for quality assurance. You’d need to merge first and initiate the QA process
PR 4: Delete the legacy code

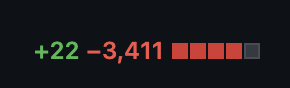
Is it just me, or do you enjoy seeing a PR where there are no new additions but a few hundred lines of deletion? This step is optional and can be carried out in the previous step. There are a couple of reasons why you can do this as a separate step. One, when you delete the legacy in the previous step, it adds more files to the PR and can be distracting to the reviewers. Second, sometimes you may need to roll out the new code gradually and still may need to support the old code. Also, you can move faster to QE/QA in the previous step and keep this task independent of the release cycle.
Building behind a feature flag
if (FeatureFlag.newTier.isEnabled()) {
executeNewFlow()
} else {
executeOldFlow()
}The next ingredient of moving faster is to build new features or refactor behind a feature flag. It took some time to identify what type of feature flag fits well for your product, but once that is up and running in your codebase, you will never go back. Here are the benefits of using a feature flag.
- You can ship unfinished code that hides behind the feature flag – this eliminates the possibility of holding the feature branches alive for a long time. You can simply merge all smaller PRs (like explained above) behind the flag.
- You can release the new feature or code in a phased rollout if the feature flag is controlled remotely. If anything goes wrong, you can roll back immediately and fix the issue on the next release.
- You can allow QE/QA to gradually test the new changes if the flag can be turned on/off from a debug menu for your nightly builds or the internal testing builds
Let me give you a real example of how the feature flag facilitated the refactoring initiative of one of the important features of our app. Based on the planning, we figured out that it would take at least three months to move this user journey to the new code (end-to-end) completely. So, to break this down into smaller releasable entities, we first identified which option is used by the majority of the users (from performance tracing). With this information, we identified a use case that the majority of our users use and refactored this first – behind a feature flag, of course, and shipped it faster. We were able to measure the impact on the experience of the new code, and this, in turn, fueled us and the management to invest more time to optimise this user journey. Over the course of 3 months, even before the feature was completely refactored, we were able to gradually release, test, measure and optimise behind the feature flag.
The feature flag can be as simple as a local boolean or controlled remotely such as Firebase remote config or Amplitude feature flag.
Trusting your team
The first paradigm shift was for the PR creator, and this cultural shift is for the reviewers, aka the team. I have worked in teams where there would be one lead or principal or staff engineer who acts as a gatekeeper to keep the codebase clean. Their influence stretches from the recommendation of the solution to the nitpicks in the name of the variables and style of the code. There is nothing wrong with it, and I used to be that guy in the past – where I would feel that people would sneakily put some bad code into the codebase. Well, over the years, I’ve intentionally loosened up a little. I’ve shifted my approach from enforcing this via the PR reviews to setting up an environment that will not allow the developers (including me) to deviate from our agreed guidelines. Such as automatic code formatting, setting up the pipeline to fail if there are missed unit tests etc. Also, when we are shipping the big feature via smaller PRs, there is always an opportunity for the developer to address some of the comments in the next PR. As a team, we must trust and give this opportunity to our developers. For example, if one of the edge case handling has been missed, we can say that this needs to be done while the current tests and the functions are valid, we encourage the devs to merge this and create a new small PR addressing just that change. Assuming things haven’t been released yet and it is behind a feature flag. This ensures that the momentum is kept while merging faster. With nitpicks – we always leave the developer to decide if they want to address it now or later.
Code walkthrough via comments

I noticed a pattern during the review process. There was always a specific type of question like “Why did you decide x?” – this usually arises when other devs try to understand your thought process. Mostly, there won’t be right or wrong decisions, but out of curiosity, everyone would want to know why you decided to take this route. For smaller PRs, are there any additional improvements coming in the upcoming PR? These questions were the point of inception for longer discussion in the PR review process, and they can take time to go back and forth to answer a lot of things. I started experimenting by giving a high-level walkthrough of the PR by setting a proper expectation on what to review for and what not in the PR description. Then, I marked the important lines of the PR (not all, but just the main change of that PR) with a comment explaining my thought process. I also marked the part of the PR which doesn’t need review or comment mentioning that more changes are expected in the upcoming PRs. For a team of five, I received the feedback that these comments helped the devs to understand better on what they are reviewing and the team was very much comfortable following this habit.
Final thoughts
I believe when the teams merge faster, they ship things faster. The momentum is kept on the initiative and pivoting or measuring becomes a lot easier. While we ship iteratively, we can also get the feedback iteratively. Before picking up the ticket, planning is super essential to break the task into smaller entities or smaller releasable entities. The above-mentioned techniques are not just theories but have been applied for more than two years within the team. You may not be in a team of similar size or product or in a similar situation, so please treat these as just tools and pick the one that best suits your needs.